When it comes to literary research, Literature Online is no doubt one of the best digital resources around. The site hosts a third of a million full-length texts, the definitive collection of digitized criticism, and a robust interface that boasts such advanced features as lemmatized and fuzzy spelling search options. When I started looking for a public API that would allow users to mobilize the site’s resources in an algorithmic fashion, though, there was no API to be found. So I decided to build my own.
Using Python’s Selenium package, I built an API that sends queries to Literature Online in a procedural fashion and generates clean, user-friendly output data. The program runs as follows: After double-clicking the literatureonlineapi.exe file (or the literatureonlineapi.app file) linked in the Tools tab of this site, the following GUI appears:
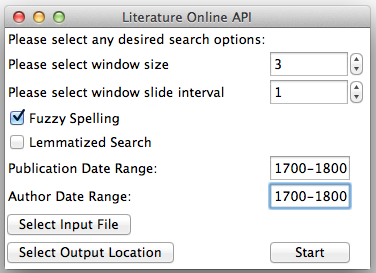
Using this interface, users may select the appropriate checkboxes pictured above to identify whether they would like to employ Literature Online’s fuzzy spelling and/or lemmatized search features. Additionally, users can limit potential matches by publication date and author date ranges. Then, users may click the “Select Input File” button to select a file they would like to use to query Literature Online. This file should be a plain text file that contains one or more words or series of words one would like to use to search Literature Online. The program will send the first n words of this file to Literature Online, where n = the value of “window size” (in the image above, n = 3). The program will then record the name, publication date, and author of texts that contain the first n words of your file. This match will be an exact match–i.e. if n = 3 and the first three words of your file are “the king will”, the program will find all texts in the Literature Online database that contain the exact string “the king will”.
Then the script will look at words p through n + p in your plain text file, where p = window slide interval. In the image above, p = 1 and n = 3, so in its second pass through our hypothetical text file the program would look at words 2 through 4 (inclusive). The program will once again pull down all relevant metadata for the found hits. It will then slide p words forward once again, examining words 3 through 5, and so forth, until it reaches the end of the document. Then, once it has reached the end, it will go back to the beginning of the document and repeat the process, this time submitting not exact searches, but proximity searches. E.g. instead of searching “the king will”, the program will find all instances of “the near.3 king near.3 will” and then slide its search window forward in the customary fashion. Finally, the program will write its .tsv output to the directory selected with the “Select Output Location” button. In the case of the sample string discussed in this paragraph, the output file looks like this:
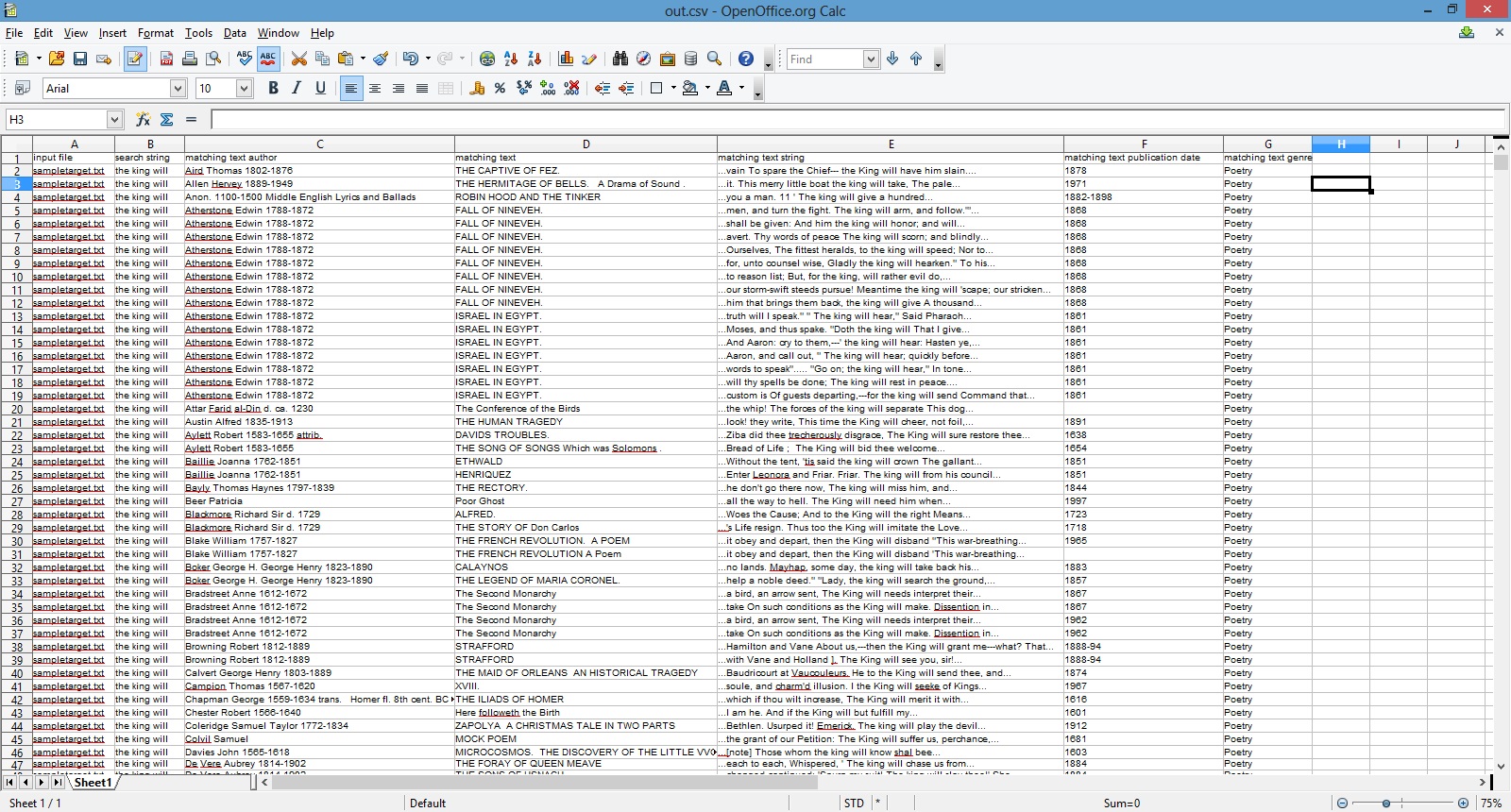
Users can then use this output to create plots, inform stylometric analysis, or simply to help allocate their readerly attention in a more efficient manner.
Let’s suppose you wanted to find all texts in the Literature Online database that contain the word “king,” as well as all of the texts that contain the word “queen.” In this case, you could proceed as follows: First, make sure you have Firefox installed on your computer. Then, download the LiteratureOnlineAPI folder, open it up, and double click the file entitled “literatureonlineapi.exe”. If you double click that file, the GUI pictured above should appear. Next, create and save a text file that contains only “king queen”. After selecting this file with the “Select File” button, set the “window size” to 1. Doing so will tell the program that you want each of the searches you send to Literature Online to contain exactly one word (where a word is defined as any character or series of characters bounded by whitespace).
Next, set the slide interval to 1, so that the program will know to send the first query (“king”), then slide forward 1 word to “queen” and submit that search term. Finally, click Start. If all goes to plan, a Firefox window will open up and the program will be off and running. If you need to terminate the program, just close that Firefox window. Doing so, however, will prevent the out.tsv output from documenting any found matches. If this happens, you can merely restart the program.
Building this tool was a blast, not least of all because doing so allowed me to learn much more about Webdriver, GUIs, and code compilation. Here’s hoping the finished tool will help others create stimulating literary and historical research!
2017 Update: The New Oxford Shakespeare Published
In 2017, Oxford University Press published the volume for which the tool described above was built–The New Oxford Shakespeare:

This collection of volumes contains an enormous wealth of scholarship that revises our understanding of the works of William Shakespeare. The Authorship Companion volume in the collection focuses in particular on reassessing the body of work that William Shakespeare wrote, leveraging stylometric analysis to isolate the portions of Shakespeare’s plays most probably written by playwrights with whom the bard collaborated (a common practice in his day).
The premier Shakespearean Gary Taylor wrote a tremendous amount of scholarship for this collection, including a chapter on which we collaborated using the tool described above. If you have a chance to review the stylometric work we undertake in the volume, it would be great to hear your thoughts:
I’ll close by noting that the LION API itself is no longer publicly available, but ProQuest does make raw data exports available for partner institutions in case other data-driver scholars wish to conduct related research.