In her fantastic series of lectures on early modern England, Emma Smith identifies an interesting feature that differentiates the tragedies and comedies of Elizabethan drama: ‘Tragedies tend to have more streamlined plots, or less plot—you know, fewer things happening. Comedies tend to enjoy a multiplication of characters, disguises, and trickeries. I mean, you could partly think about the way [tragedies tend to move] towards the isolation of a single figure on the stage, getting rid of other people, moving towards a kind of solitude, whereas comedies tend to end with a big scene at the end where everybody’s on stage’ (6:02-6:37).
The distinction Smith draws between tragedies and comedies is fairly intuitive: tragedies isolate the poor player that struts and frets his hour upon the stage and then is heard no more. Comedies, on the other hand, aggregate characters in order to facilitate comedic trickery and tidy marriage plots. While this discrepancy seemed promising, I couldn’t help but wonder whether computational analysis would bear out the hypothesis. Inspired by the recent proliferation of computer-assisted genre classifications of Shakespeare’s plays—many of which are founded upon high dimensional data sets like those generated by DocuScope—I was curious to know if paying attention to the number of characters on stage in Shakespearean drama could help provide additional feature sets with which to carry out this task.
To pursue the question, I ran some analysis on the Folger Digital Texts edition of the Bard’s plays. This delightful collection uses a custom XML schema to indicate when characters enter and exit the stage, which makes it possible to track the number of characters on stage over the course of a play:
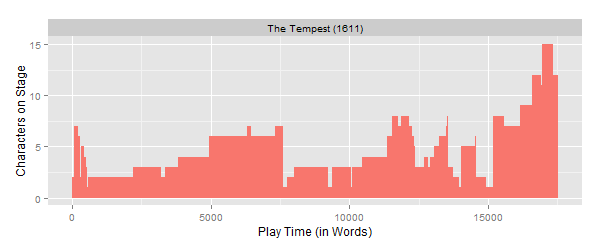
This visualization of The Tempest, for instance, traces the number of characters on stage from the play’s opening scene—in which the Shipmaster and his Boatswain are quickly joined by Alonso, Sebastian, Antonio, Ferdinand, and Ganzalo—through Prospero’s staff-dashing monologue around the 15,000 word mark to the play’s crowded conclusion. Here are the stagings for the other Shakespearean plays in the FDT canon, ordered by their date of first performance according to Alfred Harbage’s Annals of English Drama:
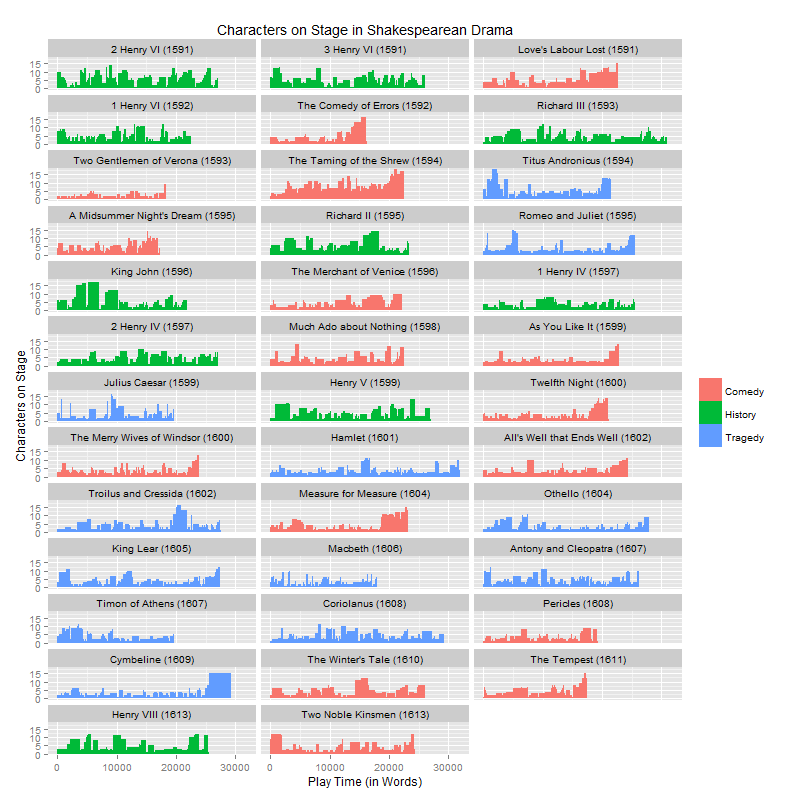
These plots afford ample evidence to suggest that Shakespearean comedies tend to end with large scenes in which everybody’s on stage. Unfortunately, many of the comedies and tragedies also end with large gatherings of characters. It therefore seems that the number of characters on stage during a play’s conclusion might not be an ideal feature with which to classify the genres of Shakespeare’s plays.
With these results in hand, I decided to measure how often Shakespeare isolates a single character on stage within plays from each of the three canonical genres. Aggregating the total number of words spoken when only a single character is on stage, as well as the total number of words spoken when only two characters are on stage, and so forth, allows one to measure the degree to which each play distributes its attention between large and small gatherings of characters (click to enlarge):
While these plots reveal some interesting features of the works, such as the fact that Two Gentlemen of Verona truly does revolve around dyadic pairs, they make it difficult to compare the amount of time tragedies and comedies feature only a single character on stage. To make this latter comparison, one can find the average amount of time a single character occupies the stage for each genre:
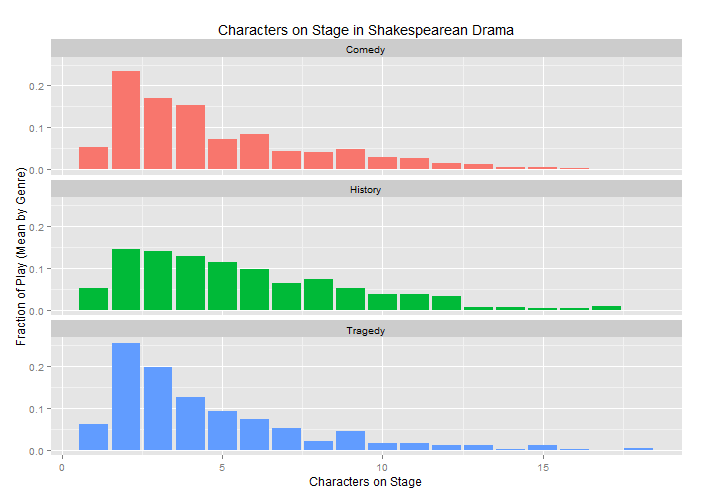
Surprisingly, the chief difference between the comedies and tragedies has less to do with the way each handles isolated actors on stage than with the way each handles triads and quadrads. It seems tragedies have a greater tendency to revolve around sets of three characters, while comedies are more often organized around sets of four characters. That said, the similarities between the two genres are far more striking than their differences, and far less encouraging for one in search of distinguishing features.
Reflecting on these results, I wondered if tragedies might be better classified by the amount of time their conflicted characters spend addressing the audience. One way to begin measuring the latter, I thought, would be to count the number of words spoken by each character in each play (click to enlarge):
Analyzing these figures, I was struck by what should have been a fairly obvious fact: Shakespeare’s most memorable characters (Falstaff, Hal, Prospero, Rosalind, Hamlet…) are each given commanding positions within the plays they lead. Given the strong correlation between these memorable characters and the number of lines each speaks, it’s tempting to ask whether we remember these characters most readily simply because Shakespeare allowed them to say the most, or whether Shakespeare allowed them to say the most because he sensed they were his most memorable characters.
Either way, the last trio of plots shows a fairly even distribution of commanding figures among the comedies, histories, and tragedies. But those plots also reveal that the histories include rather few words spoken by women, as well as the fact that the comedies tend to be shorter than the tragedies and histories:
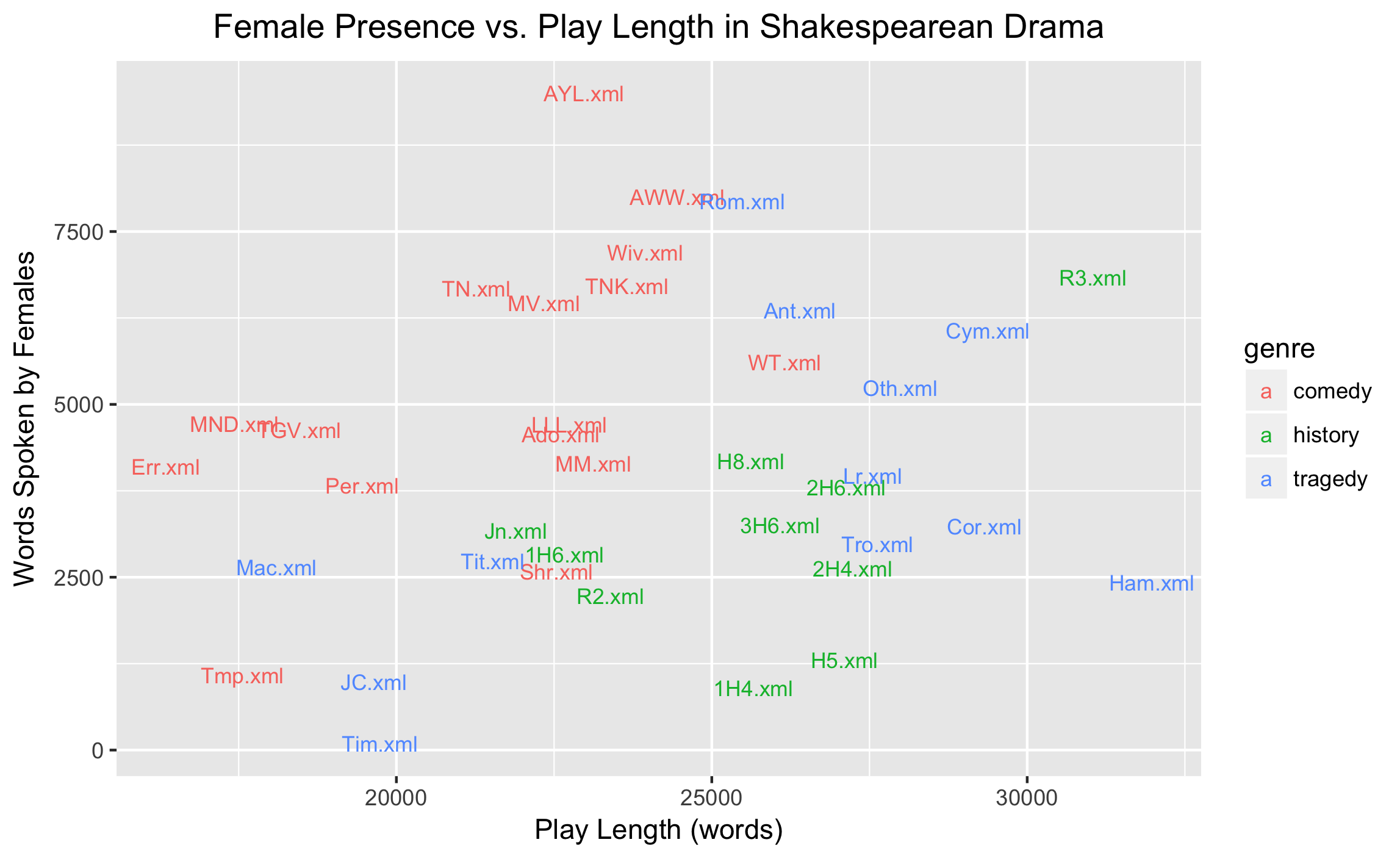
By analyzing only the length of a play and the number of words women speak in that play, one can start to get reasonably good separation between the genres: comedies tend to be shorter and include more female dialogue, histories tend to be longer and include less female dialogue, and tragedies split provocatively between the upper right and lower left. Reviewing these figures, I can’t shake the suspicion that a third dimension of data could unite these divided tragedies. But what would that dimension consist of?
I would like to thank Mike Poston, co-curator of the Folger Digital Text editions used for this analysis, for discussing many of the finer points of the FDT collection with me. In case you want to replicate any of the analysis or assess the assumptions on which it’s founded, the scripts are here.