When Samuel Richardson’s Mrs. Jewkes remarks that ‘Nought can restrain consent of twain,’ we confidently conclude she’s quoting Harington’s translation of Orlando Furioso. When Edmund Burke writes in his Philosophical Enquiry, ‘Dark with excessive light thy skirts appear,’ we know he’s misquoting Milton. While passages like these make their debts fairly clear, though, in most cases literary influence is notoriously difficult to trace. When Mary Wollstonecraft identifies marriage as a form of ‘legal prostitution’ in her Vindications, for instance, are we meant to reflect on the thrust of that phrase in Defoe’s Matrimonial Whoredom? When Ann Radcliffe’s Adeline and La Motte stroll ‘under the shade of ‘melancholy boughs’’ in The Romance of the Forest, what gives us the warrant to imagine Orlando ‘under the shade of melancholy boughs’ in As You Like It?
In each of the aforementioned cases, both the quoting and the quoted texts include identical (or nearly-identical) sequences of words. If this property is a necessary condition for intertextuality, however, it is clearly not a sufficient one, for while Wollstonecraft’s second Vindication and Defoe’s Matrimonial Whoredom both use the phrase ‘legal prostitution,’ they also both use the phrase ‘if it be,’ as well as the phrase ‘a kind of.’ Nonetheless, literary scholars don’t identify the latter two strings as instances of intertextuality, perhaps because we intuitively sense that ‘if it be’ and ‘a kind of’ are far more common phrases during the period than ‘legal prostitution,’ a thesis to which Google lends some confidence:
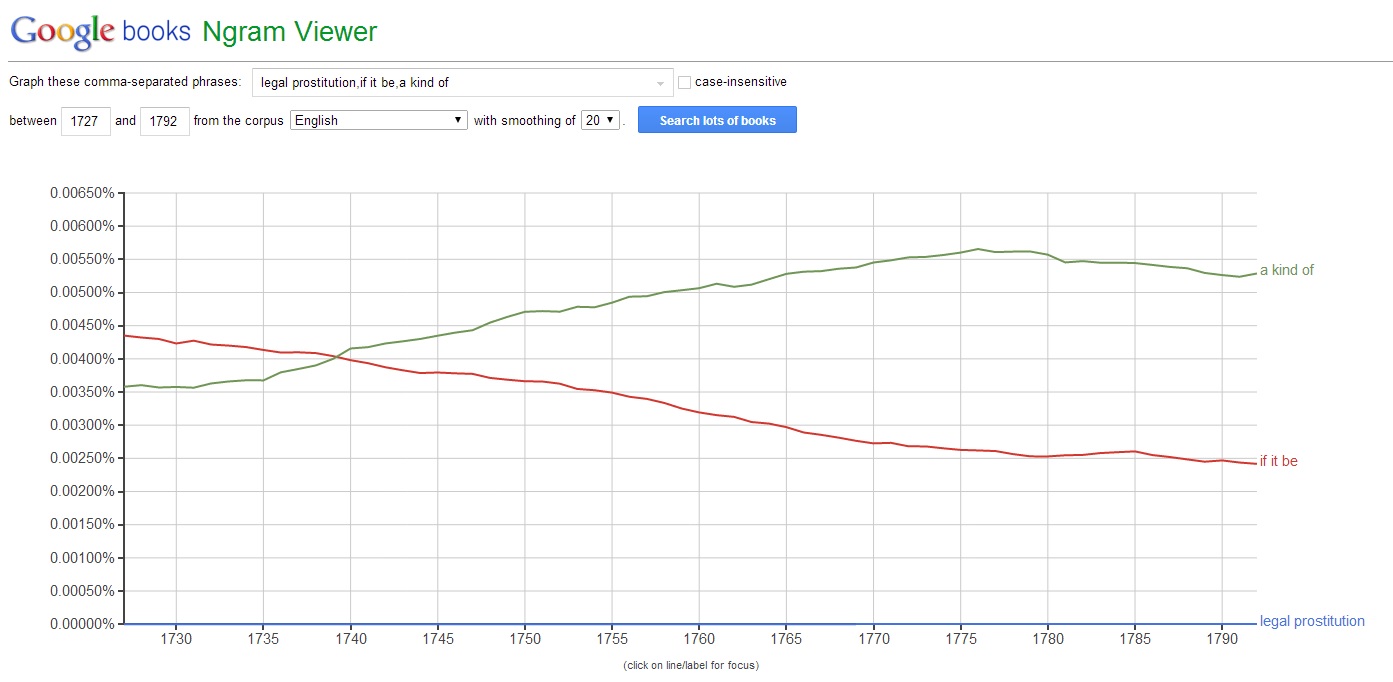
Such queries demonstrate something literary scholars have known for a long time, namely the fact that the passages we classify as instances of intertextuality have (1) common words in a common order, and (2) significantly lower relative frequency rates than other (equally long) strings from the same period. With this insight in mind, I built an API for the Google Ngrams data with which one can pull down the relative frequencies of a list of strings shared by two (or more) works. Given a set of substrings shared by two texts, and given the relative frequencies of each of those strings in the age during which those texts were published, one can eliminate high frequency strings and thereby reduce the number of passages scholars must hand review to identify relevant instances of intertextuality.
Although I developed the Ngram API to eliminate high frequency strings from the output of my sequence alignment routines, it eventually helped me to discover an interesting correlation between the relative frequency of n-grams and instances of intertextuality. This discovery unfolded in the following way. On a whim, I decided to examine the relative frequencies of bigrams across passages from a few canonical works published during the long eighteenth century: Henry Fielding’s Joseph Andrews (1742), Edmund Burke’s Enquiry (1757), and Maria Edgeworth’s Ennui (1809). Each of the selections that I drew from these texts centers on a quotation of another writer—the Fielding passage quotes Virgil’s Aeneid, the Burke passage quotes Shakespeare’s Henry V, and the Edgeworth passage quotes Voltaire’s ‘La Bégueule.’ I broke each of these passages down into a set of sequential bigrams, and submitted each of the bigrams to the Google Ngrams data via the API described above. In the case of Burke, for example, I fired up the API and entered the following data into the input fields:
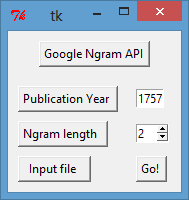
After identifying these parameters and clicking ‘Go!’, I watched the tool navigate to the Google Ngram site and search for the relative frequency of the first two words in the Burke passage. The API limits the historical scope of this search to the period between 1752 and 1762 (the user-provided publication date of Burke’s text plus and minus five years), because the Google Ngram data is a bit noisy, and we don’t want anomalies in the data for 1757 to skew our sense of the bigram’s relative frequency in the period. The API then calculates the mean value for the bigram’s relative frequency across those years, and it writes the bigram, the publication year, and the calculated relative frequency to an output file. It then looks at the next bigram (containing words two and three), and reiterates the process, continuing in this fashion until it has queried all valid ngrams in the input file.
Preliminary analysis suggests that one can then use this output file to identify instances of intertextuality, even in cases in which one does not have access to the referenced text. (This task is referred to as ‘intrinsic plagiarism detection’ within related scholarship.) Using the aforementioned selections from eighteenth-century texts, I used the method described above to calculate the relative frequencies of the bigrams in each of those selections. I then plotted the bigram frequencies with R’s scatter.smooth() function—identifying the first bigram in the selection as bigram number one, the second bigram as bigram number two, and so forth across the x-axis—so that I could better identify the trends in bigram frequency across each passage. I was surprised by the results (click to enlarge):
In each case, the local minimum of the regression line centers on the instance of intertextuality in the queried passage! While this trend is promising, though, it could be due to a number of causes. Chief among these are the differences in language and historical period that divide each of the ‘quoting’ texts cited above from the passage that that work quotes. As we noted above, Henry Fielding quotes Virgil, Burke quotes Shakespeare, and Edgeworth quotes Voltaire, all in the original languages. When we compare the relative frequency of bigrams in Latin, French, and Elizabethan English with bigrams written in colloquial English of the mid- to late-eighteenth century, then, we should perhaps not be surprised that the latter tend to be more common in the Ngram data from that period, ceteris paribus.
These initial results yield new questions: Can the method described above identify instances of poetry in works of prose from a particular period? Can such a method be integrated into an ensemble approach to intertextuality, or do these graphs merely contain a half-told truth, mysterious to descry, which in the womb of distant causes lie? Such are the questions I hope to pursue in subsequent work.